This post contains a simple function that creates formatted drift-diffusion plots using matplotlib in Python. Drift-diffusion plots show how something "drifts" between two bounds over time. They're commonly used to visualize how people reach decisions after accumulating information. Here's an example of a drift-diffusion plot showing the average "drift" of multiple trials or instances:

I wrote this function when I was analyzing data from one of my experiments. In the experiment, participants had to guess which of two options was correct based on a stream of incoming evidence. The drift-diffusion plots represented their guesses (ranging from 100% certain option A was correct to 100% certain option B was correct) over time.
You can view and download the Jupyter notebook I made to create the plots here.
First, we'll import libraries, define some formatting, and create some data to plot.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#set font size of labels on matplotlib plots
plt.rc('font', size=16)
#define a custom palette
customPalette = ['#630C3A', '#39C8C6', '#D3500C', '#FFB139']
plt.rcParams['axes.prop_cycle'] = plt.cycler(color=customPalette)
t = 100 #number of timepoints
n = 20 #number of timeseries
bias = 0.1 #bias in random walk
#generate "biased random walk" timeseries
data = pd.DataFrame(np.reshape(np.cumsum(np.random.randn(t,n)+bias,axis=0),(t,n)))
data.head()
DRIFT-DIFFUSION PLOT FUNCTION
def drift_diffusion_plot(values, upperbound, lowerbound,
upperlabel='', lowerlabel='',
stickybounds=True, **kwargs):
"""
Creates a formatted drift-diffusion plot for a given timeseries.
Inputs:
- values: array of values in timeseries
- upperbound: numeric value of upper bound
- lowerbound: numeric value of lower bound
- upperlabel: optional label for upper bound
- lowerlabel: optional label for lower bound
- stickybounds: if true, timeseries stops when bound is hit
- kwargs: https://matplotlib.org/api/_as_gen/matplotlib.pyplot.plot.html
Output:
- ax: handle to plot axis
"""
#if bounds are sticky, hide timepoints that follow the first bound hit
if stickybounds:
#check to see if (and when) a bound was hit
bound_hits = np.where((values>upperbound) | (values<lowerbound))[0]
#if a bound was hit, replace subsequent values with NaN
if len(bound_hits)>0:
values = values.copy()
values[bound_hits[0]+1:] = np.nan
#plot timeseries
ax = plt.gca()
plt.plot(values, **kwargs)
#format plot
ax.set_ylim(lowerbound, upperbound)
ax.set_yticks([lowerbound,upperbound])
ax.set_yticklabels([lowerlabel,upperlabel])
ax.axhline(y=np.mean([upperbound, lowerbound]), color='lightgray', zorder=0)
ax.set_xlim(0,len(values))
ax.set_xlabel('time')
ax.spines['left'].set_visible(False)
ax.spines['right'].set_visible(False)
return ax
PLOT A SINGLE TIME SERIES WITHOUT STICKY BOUNDS
You can specify if the plot should have sticky bounds or not. Setting stickybounds=TRUE prevents the time series from moving away from a bound once it is reached. This is equivalent to forcing "decisions" to be final. Setting stickybounds=FALSE allows the time series to move away from a bound.
ax = drift_diffusion_plot(data.iloc[:,4], upperbound=10, lowerbound=-10,
upperlabel='Bound A ', lowerlabel='Bound B ',
stickybounds=False)

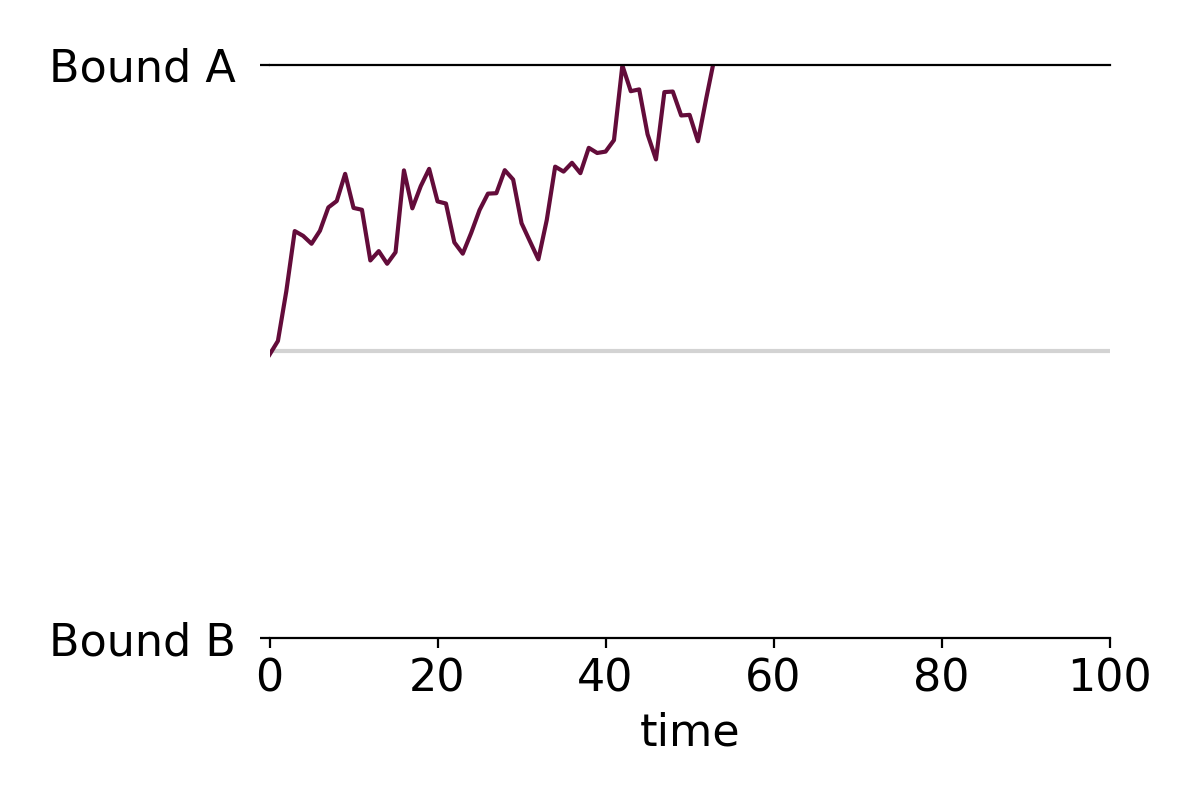
PLOT A SINGLE TIME SERIES WITH STICKY BOUNDS (DEFAULT)
ax = drift_diffusion_plot(data.iloc[:,4], upperbound=10, lowerbound=-10,
upperlabel='Bound A ', lowerlabel='Bound B ')
CUSTOMIZE FORMATTING
You can customize the plot in several ways. First, you can pass in any of the kwarg arguments accepted by Matplotlib in the drift_diffusion_plot function. Here's a list of arguments you can pass in. Second, the function returns a handle to the plot's axis that you can use to further adjust the formatting.
#you can pass in any of the kwargs that matplotlib accepts
ax = drift_diffusion_plot(data.iloc[:,4], upperbound=10, lowerbound=-10,
stickybounds=False,
lw=2.5, ls=':', color=customPalette[1])
#return the axis to make additional changes
ax.set_xlabel(''); #remove x label
ax.set_xticks([0,31,59,90]) #adjust x ticks
ax.set_xticklabels(['Jan','Feb','Mar','Apr'], #change x tick labels
size=14, color='gray');
ax.set_yticklabels(['BUY ','SELL ']) #add y tick labels
ax.set_ylabel('price') #add y label

PLOT MULTIPLE TIME SERIES AND OVERLAY THE MEAN
You can easily apply the function to multiple time series. For example, making a plot with all individual time series along with the mean time series takes only two lines of code:
#plot individual timeseries
data.apply(drift_diffusion_plot, upperbound=10, lowerbound=-10, color='black', alpha=0.2);
#plot mean timeseries
drift_diffusion_plot(np.mean(data, axis=1), upperbound=10, lowerbound=-10,
upperlabel='Bound A ', lowerlabel='Bound B ',
color='black', lw=3);

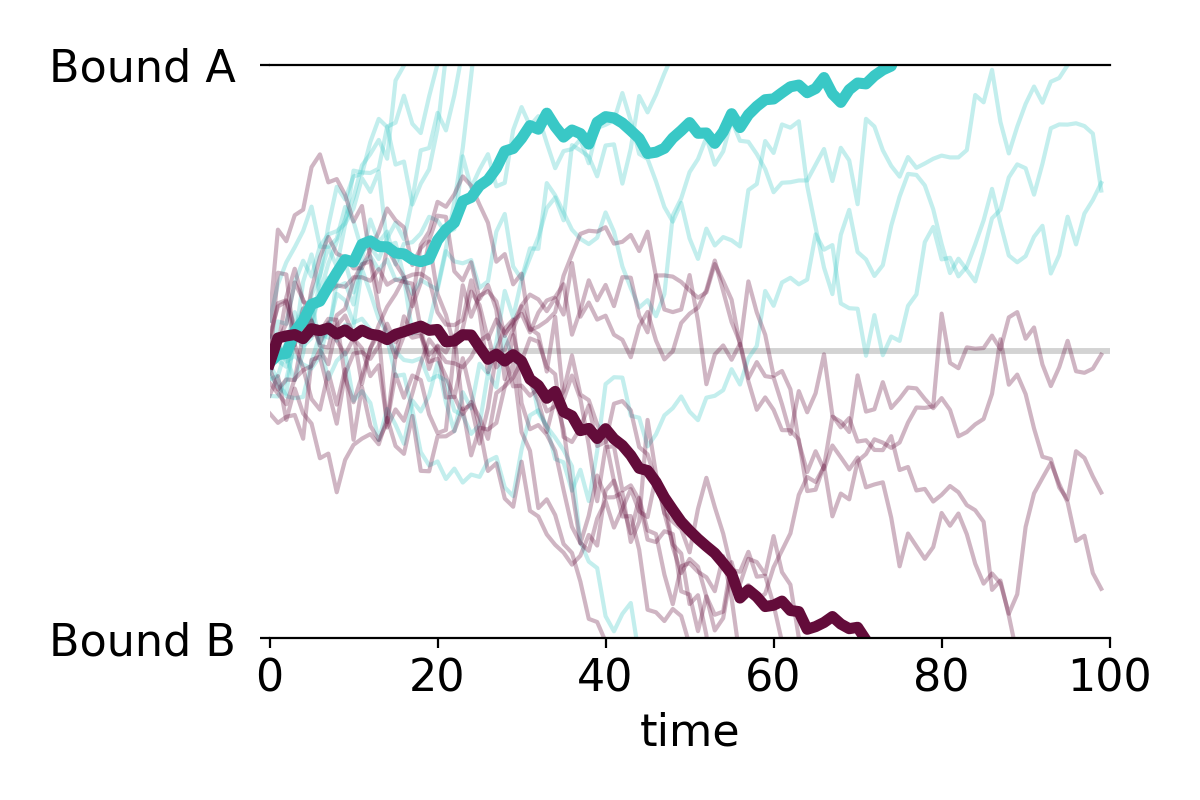
PLOT MULTIPLE GROUPS
We can also plot the individual time series in two or more color-coded groups.
n=10
#group 1 (positive drift)
data1 = pd.DataFrame(np.reshape(np.cumsum(np.random.randn(t,n)+bias,axis=0),(t,n)))
data1.apply(drift_diffusion_plot, upperbound=10, lowerbound=-10,
color=customPalette[1], alpha=0.3);
drift_diffusion_plot(np.mean(data1, axis=1), upperbound=10, lowerbound=-10,
color=customPalette[1], lw=4, alpha=1);
#group 2 (negative drift)
data2 = pd.DataFrame(np.reshape(np.cumsum(np.random.randn(t,n)-bias,axis=0),(t,n)))
data2.apply(drift_diffusion_plot, upperbound=10, lowerbound=-10,
color=customPalette[0], alpha=0.3);
drift_diffusion_plot(np.mean(data2, axis=1), upperbound=10, lowerbound=-10,
upperlabel='Bound A ', lowerlabel='Bound B ',
color=customPalette[0], lw=4, alpha=1);
CNS 2018: tDCS-induced hemispheric asymmetry alters belief updating
This year at the Cognitive Neuroscience Society conference we're presenting our first set of high-definition transcranial Direct Current Stimulation (HD-tDCS) results.
We used tDCS to temporarily alter neural activity in participants' left and right frontal lobes in order to test our predictions about hemispheric asymmetry in reasoning. We applied 2mA of anodal stimulation to the inferior frontal gyrus of one hemisphere and 2mA of cathodal stimulation to the inferior frontal gyrus of the opposite hemisphere to temporarily bias neural activity toward the left (LH-bias stimulation) or right (RH-bias stimulation) hemisphere. Participants completed a probabilistic guessing task while receiving LH-bias, RH-bias, or sham stimulation.
We found that, as predicted, LH-bias stimulation was associated with more certain guesses early on in each trial. However, there was no effect on the amount of evidence collected or the evidence threshold set for deciding to stop evidence collection. Contrary to our predictions, RH-bias stimulation was not associated with greater "backtracks" in beliefs following conflicting evidence. It's possible that this task did not induce salient conflicts between beliefs and evidence since the stimuli were abstract and inconsequential. To see if RH-bias stimulation affects belief updating under more meaningful belief-evidence conflicts, we are currently running a new tDCS experiment that uses more realistic and emotionally-salient stimuli.

30 years of trends in the MRI and fMRI literatures
When I entered graduate school, I knew next to nothing about functional magnetic resonance imaging (fMRI) and it's history. I eventually began to piece together a picture of fMRI's more recent history as I started to notice certain topics permeating conferences, classes, and conversations. Even so, I've long been curious about what topics shaped the fMRI and MRI literatures over time. When I learned about burst detection, I immediately wanted to use the method to create a data-driven timeline of fMRI.
(You can view the Jupyter notebook I made to run all the analyses here. If you want to read more about burst detection, you can read this blog post, and if you want to apply burst detection analysis to your own data, you can download the burst detection package I compiled on PyPi.)
DATASET oF MRI ARTICLES
I used the PubMed database to collect the titles of MRI articles. I searched for the terms "fMRI" or "MRI" in the title/abstract field and restricted the results to articles and review papers published between 01/01/1987 and 11/30/17 and written in English. PubMed expanded the search to documents including the phrases "magnetic resonance imaging" or "functional magnetic resonance imaging" in the title or abstract. The search returned a total of 410,100 documents (accessed on 12/15/2017).
I only kept articles with publication dates that included a month and a year. Articles that had no publication date at all, no publication month, a season rather than a month, or that were published outside the date range were discarded, leaving a total of 371,244 documents.
If we look at how many MRI articles were published every month during the timeframe, we can see an almost linear (maybe exponential) increase in the number of articles published from 1987 to 2015, and then a slight decline. I don't know if this decline is due to some shift in the field -- maybe fewer articles contain the terms "fMRI" or "MRI" now or maybe fewer fMRI articles are being published -- or if it's reflective of some sort of delay in PubMed's indexing of articles.
It looks like approximately (a whopping!) 2000 MRI and fMRI articles have been published every month since 2014. That is much more than I would have guessed. Granted, these may not all be actual MRI or fMRI studies. The search returned all documents that contained fMRI or MRI in the title or abstract, but it's unclear whether those articles published new results or simply referenced previous studies.
PREPROCESSING ARTICLE TITLES
Since this analysis tracks how often different words appear in MRI article titles over time, I first had to preprocess the titles in the dataset. Preprocessing was pretty minimal -- I simply converted all words to lowercase, stripped all punctuation, and split each title into individual words. The titles in the dataset contained 101,843 unique words. A large chunk of these words only appeared a few times. Since I'm interested in general trends, I don't really care about words that rarely appear in the literature. In order to weed out uncommon words and reduce computation time later on, I discarded all words that appeared fewer than 50 times in the dataset. That left 6,310 unique words.
I was curious about what words are used the most in MRI and fMRI article titles. Not surprisingly, some of the most common words were magnetic, resonance, and imaging (which were part of the search terms) and common articles and prepositions, such as the, of, and a. Ignoring these words, the most frequently used word in all MRI titles is.... brain! Also not very surprising. Here are the remaining 49 most common words in the dataset:
One thing about this list I found surprising is how medically-oriented most of the terms are. Since I'm surrounded by researchers who use fMRI to study cognition, I expected words like memory, executive, network, or activity to top the list, but they don't even appear in the top 50! I suspect there are two primary factors contributing to the medical nature of these words. First, the articles returned by searching for "MRI" are likely to be medical in nature since MRI has a myriad of medical imaging applications, including detecting tumors, internal bleeds, demyelination, and aneurysms. Accordingly, some of the most prevalent words reflect these applications, such as cancer, spinal, tumor, artery, lesions, sclerosis, cardiac, carcinoma, breast, stroke, cervical, and liver. Second, I used the full dataset -- which spanned 1987 to 2017 -- to identify the most common words, which biases terms that were prevalent throughout the full period. Since functional imaging didn't become widespread until a few years after anatomical imaging, it's less likely that functional-related terms would make into the most common words.
Next, I wanted to zoom in on MRI's more recent history and look at how the ranks of the most prevalent words changed over the last 10 years. I pulled out all article titles published since 2007 and found the top 15 most frequent words. Here are the counts of those top 15 words over the past 10 years:

This chart illustrates that the terms brain, patients, and study have been and still are the most popular words in fMRI and MRI article titles. In comparison, the popularity of case has declined over the last few years. In 2007, it was just as common as brain, patients, and study, but by 2017 it is used nearly 50% less often than these other terms. The terms disease, after, clinical, cancer, report, and syndrome all saw small dips after 2016 after long periods of continual increases, which may reflect the dip in the number of articles published in 2016 and 2017 (it may also reflect the fact that the data for 2017 doesn't include December). The term functional saw a large gain in the last 10 years, rising from the 9th spot in 2007 to the 4th spot in 2017. This may reflect the growing proportion of fMRI papers in the MRI literature or it may reflect the growing popularity of functional connectivity.
FINDING FADS WITH BURST DETECTION
Looking at the most common words in the dataset gives us an idea about what topics are prevalent in the fMRI literature, but it doesn't give us a great idea about what topics are trending. For example, the word carcinoma appears in the dataset frequently, but its use hasn't really changed since 1987:

This differs from angiography and connectivity, which appear in the dataset about as frequently as carcinoma (the dotted lines represent the overall fraction of titles that contain each word), but are characterized by different time courses. Angiography was popular in the 1990s, but has since become less popular. In contrast, connectivity was virtually unused before 2005, but has since seen a meteoric rise.
To find fads in the MRI literature, we can turn to burst detection. Burst detection finds periods of time in which a target is uncharacteristically popular, or, in other words, when it is "bursting." In our case, the target is one of the unique words in the dataset and we are looking for periods in which the word appears in a greater proportion of article titles than usual. The two-state model that I used assumes that a target can be in one of two states: a baseline state, in which the target occurs at some baseline or default rate, and a bursty state, in which the target occurs at an elevated rate. For every time point (in this case, for every month), the algorithm compares the frequency of the target at that time point to the frequency of the target over the full time period (the baseline rate) and tries to guess whether the target is in a baseline state or a bursty state. The algorithm returns its best guess of which state the target was in at each time point during the time period. In the example above, we would not expect carcinoma to enter a bursty state because the proportions don't get much greater than the baseline proportion (gray dotted line). However, we would expect connectivity to enter a burst state some time around 2014 because the proportions begin to far exceed the baseline proportion (blue dotted line).
There are a few parameters you can tweak in burst detection. The first is the "distance" between the baseline state and burst state. I used s=2 which means that a word has to occur with a frequency that is more than double its baseline frequency to be considered bursting. The second is the difficulty associated with moving up into a bursty state. I used gamma=0.5, which makes it relatively easy to enter a bursting state. Finally, I smoothed the time courses with a 5-month rolling window to reduce noise and facilitate the detection of the bursts. I applied the same burst detection model to all 6,310 unique words in the dataset to determine which terms, if any, were associated with bursts of activity and when those bursts occurred.
The vast majority of terms were not associated with any bursts, but a handful of terms did exhibit bursting activity. Below is a timeline of the top 100 bursts. Each bar represents one burst, with previous bursts in gray and current bursts (those that are still in a burst state as of November 2017) in blue. Since the time courses were smoothed, the start points and end points of the bursts are not precise (notice how the current bursts end in mid 2017).

This analysis reveals a beautiful progression in the MRI literature. Imaging-related terms trend early on, with tomography, computed, resonance, mr, magnetic, nmr, nuclear, imaging, and ct bursting in the late 1980s and early 1990s. Medical terms begin to appear in the mid-1990s, including tumors, findings, evaluation, and angiography. The early 2000s are punctuated by advances in MRI technology, as demonstrated by bursts in the terms fast, three-dimensional, gamma, knife, event-related, and tensor. Bursts after 2010 capture the cognitive revolution ushered in by fMRI, with bursts in the terms cognitive, social, connectivity, resting, state, altered, network, networks, resting-state, default, and mode.
To get an idea of how well the algorithm identified bursting periods, I plotted the proportions of the bursting words throughout the time period. Since there's great variability in the baseline proportions of the words, I normalized the monthly proportions by dividing them by each word's baseline proportion. Values of 1 indicate that the proportion is equal to the baseline proportion, values less that 1 (light blue) indicate that the proportion is less than the baseline, and values greater than 1 (dark blue) indicate that the proportion is greater than the baseline. The boundaries of the bursts are outline in black.

One thing that's apparent is that the burst detection algorithm does a poor job of detecting the beginning of the bursts. Take for example the terms fast, event-related, nephrogenic, state, pet/mr, and biomarker. I can think of a few explanations for this. First, it's possible that the algorithm identified multiple bursts, but the earlier bursts were not strong enough to enter the top 100 bursts. However, after looking at all of the bursts associated with the terms listed above, it doesn't look like any additional early bursts were detected. The second, more likely explanation, is that burst detection is simply ill-suited to detect early upticks in a topic. For example, if you look back to the time course of connectivity, it looks like the term begins to gain popularity around 2005 or so. However, up until 2011, the frequency of connectivity is less than the baseline frequency so the burst detection algorithm assumes it is in the baseline state. So instead of thinking of burst detection as a method that identifies when bubbles are forming, we should think of it as finding when bubbles burst or boil over (which is maybe when a fad starts anyway?)
CURRENT TRENDS
Since burst detection does a poor job of catching topics that are just beginning to become popular, I was curious about what topics are currently trending. To find the top trending words, I found the slope of the line of best fit of each word's proportions over the last two years. Words that appeared at the same rate throughout the time period should have slopes around zero, words that became less prevalent should have negative slopes, and words that became more prevalent should have positive slopes. After removing words with baseline proportions less than 0.005, I selected the top 15 words with the steepest upward slopes. The proportions of these words since 2015 is plotted below. (The trajectories are heavily smoothed to aid visualization, but they were not smoothed when computing the slopes.)

I think the lesson here is that if you want your research to be on the cutting edge, you need to write a paper titled "Accuracy and prognostic outcomes of simultaneous multi-parametric measurements for systematically predicting adolescents' resting-state networks and prostate cord fat." .... At least, I think that's the takeaway.
Finally, here are the top 15 words that have been rising in popularity over a longer 15 year period:

Connectivity is the obvious break out star, appearing in less than 0.5% of articles in 2002 and nearly 4% of articles in 2017.
I could probably make another half dozen graphs, but I'll stop myself here. Let me know what you thought about this analysis or if you have ideas about additional things to look at. Next I'm going to work on applying the same analysis to identifying trends in the New York Times news article archive.
How to make arrow plots that visualize change
After a quick Google search, I realize that there may not be such a thing as an arrow plot and I may have made up the term. Regardless of whether it's an actual type of plot or not, I've found them useful in visualizing changes in some variable across individuals and this post describes how to make them in Python.
I first made the plot when I was trying to illustrate the variability in individuals' responses to neurostimulation. At the group level, our lab found that stimulating the right inferior frontal gyrus with repetitive Transcranial Magnetic Stimulation made participants more cautious to identify previously studied faces during a recognition memory experiment. We only observed this pattern in one condition and I wanted to visualize how participants' decision criteria changed before vs. after TMS in each condition. Normally I would use a strip plot with different colored points for before vs. after stimulation, but I thought replacing the points with an arrow pointed in the direction of the change would make for a simpler, more intuitive plot. Here's what the arrow plots looked like in the poster:
The dots in the arrow plots denote the participants' decision criteria before stimulation and the tip of the arrow heads denote their decision criteria after stimulation.
I use these plots often to visualize changes in participants' behaviors before vs. after neurostimulation, but they can be used in any situation where you need to illustrate how some variable changed among different entities. For example, you could use them to show how population changed among different US states, how mean salaries changed among different occupations, or how stock prices changed among different corporations.
You can view and download the Jupyter notebook I made to create the plots here.
First, we'll import libraries, define some formatting, and create some data to plot.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.colors
%matplotlib inline
#set font size of labels on matplotlib plots
plt.rc('font', size=16)
#set style of plots
sns.set_style('white')
n = 30 #number of subjects
#create dataframe
data = pd.DataFrame(columns=['subject','before','after','change'], index=range(n))
data.loc[:,'subject'] = range(n)
data.loc[:,'before'] = np.random.normal(0, 0.5, n)
data.loc[:,'after'] = np.random.normal(0.25, 0.5, n)
data.loc[:,'change'] = data['after'] - data['before']
data.head()
ARROW PLOT 1: BEFORE vs. AFTER VALUES
This is the same arrow plot I made for the ICB poster. The arrows start at the "before score" and end at the "after score." The participants are sorted according to how much their scores changed.
#sort individuals by amount of change, from largest to smallest
data = data.sort_values(by='change', ascending=False) \
.reset_index(drop=True)
#initialize a plot
ax = plt.figure(figsize=(5,10))
#add start points
ax = sns.stripplot(data=data,
x='before',
y='subject',
orient='h',
order=data['subject'],
size=10,
color='black')
#define arrows
arrow_starts = data['before'].values
arrow_lengths = data['after'].values - arrow_starts
#add arrows to plot
for i, subject in enumerate(data['subject']):
ax.arrow(arrow_starts[i], #x start point
i, #y start point
arrow_lengths[i], #change in x
0, #change in y
head_width=0.6, #arrow head width
head_length=0.2, #arrow head length
width=0.2, #arrow stem width
fc='black', #arrow fill color
ec='black') #arrow edge color
#format plot
ax.set_title('Scores before vs. after stimulation') #add title
ax.axvline(x=0, color='0.9', ls='--', lw=2, zorder=0) #add line at x=0
ax.grid(axis='y', color='0.9') #add a light grid
ax.set_xlim(-2,2) #set x axis limits
ax.set_xlabel('score') #label the x axis
ax.set_ylabel('participant') #label the y axis
sns.despine(left=True, bottom=True) #remove axes
ARROW PLOT 2: NORMALIZED CHANGES
This plot visualizes the change in scores, and not the scores themselves. It's effective if you want to emphasize the magnitude of change, and not the actual start points or end points. It looks cleaner, but it also conveys less information.
#sort individuals by amount of change, from largest to smallest
data = data.sort_values(by='change', ascending=True) \
.reset_index(drop=True)
#initialize a plot
fig, ax = plt.subplots(figsize=(5,10))
ax.set_xlim(-1.5,1.5)
ax.set_ylim(-1,n)
ax.set_yticks(range(n))
ax.set_yticklabels(data['subject'])
#define arrows
arrow_starts = np.repeat(0,n)
arrow_lengths = data['change'].values
#add arrows to plot
for i, subject in enumerate(data['subject']):
ax.arrow(arrow_starts[i], #x start point
i, #y start point
arrow_lengths[i], #change in x
0, #change in y
head_width=0.6, #arrow head width
head_length=0.2, #arrow head length
width=0.2, #arrow stem width
fc='black', #arrow fill color
ec='black') #arrow edge color
#format plot
ax.set_title('Changes in scores') #add title
ax.axvline(x=0, color='0.9', ls='--', lw=2, zorder=0) #add line at x=0
ax.grid(axis='y', color='0.9') #add a light grid
ax.set_xlim(-2,2) #set x axis limits
ax.set_xlabel('change') #label the x axis
ax.set_ylabel('participant') #label the y axis
sns.despine(left=True, bottom=True) #remove axes
ARROW PLOT 3: COLOR-CODED ARROWS
You can also color-code the arrows to illustrate positive or negative change:
#sort individuals by amount of change, from largest to smallest
data = data.sort_values(by='change', ascending=True) \
.reset_index(drop=True)
#initialize a plot
fig, ax = plt.subplots(figsize=(5,10)) #create figure
ax.set_xlim(-2,2) #set x axis limits
ax.set_ylim(-1,n) #set y axis limits
ax.set_yticks(range(n)) #add 0-n ticks
ax.set_yticklabels(data['subject']) #add y tick labels
#define arrows
arrow_starts = np.repeat(0,n)
arrow_lengths = data['change'].values
#add arrows to plot
for i, subject in enumerate(data['subject']):
if arrow_lengths[i] > 0:
arrow_color = '#347768'
elif arrow_lengths[i] < 0:
arrow_color = '#6B273D'
else:
arrow_color = 'black'
ax.arrow(arrow_starts[i], #x start point
i, #y start point
arrow_lengths[i], #change in x
0, #change in y
head_width=0.6, #arrow head width
head_length=0.2, #arrow head length
width=0.2, #arrow stem width
fc=arrow_color, #arrow fill color
ec=arrow_color) #arrow edge color
#format plot
ax.set_title('Changes in scores') #add title
ax.axvline(x=0, color='0.9', ls='--', lw=2, zorder=0) #add line at x=0
ax.grid(axis='y', color='0.9') #add a light grid
ax.set_xlim(-2,2) #set x axis limits
ax.set_xlabel('change') #label the x axis
ax.set_ylabel('participant') #label the y axis
sns.despine(left=True, bottom=True) #remove axes